Aperçu du projet :
Dans ce projet, nous avons conçu et mis en œuvre une architecture robuste sur Google Cloud Platform (GCP) pour rationaliser le déploiement de modèles d'apprentissage automatique et les intégrer de manière transparente dans l'environnement BigQuery. L'objectif principal était de combler le fossé entre les scientifiques des données et les analystes, en leur permettant d'utiliser des modèles d'apprentissage automatique prêts à l'emploi dans leur environnement BigQuery préféré, sans avoir besoin de connaissances techniques approfondies sur les cadres d'apprentissage automatique.
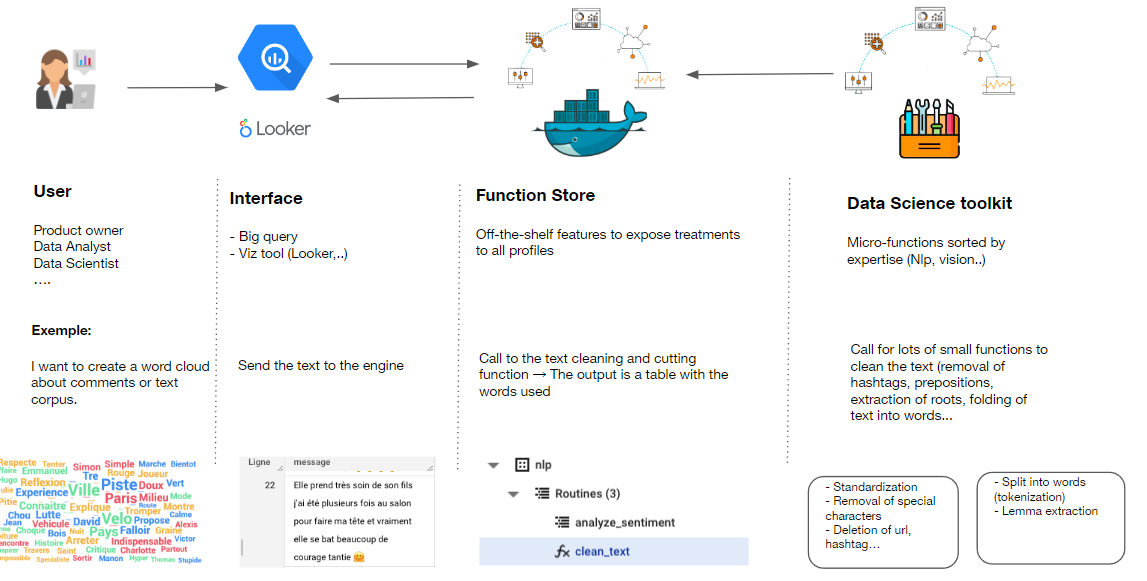
Objectifs :
- Intégration transparente : Permettre aux analystes de données d'exécuter des modèles d'apprentissage automatique dans BigQuery, en tirant parti de ses puissantes capacités d'interrogation de type SQL.
- Évolutivité : Concevoir une architecture capable de gérer de grands ensembles de données et de s'adapter aux exigences des tâches à forte intensité de données.
- Facilité d'utilisation : Créer une interface conviviale qui permette aux scientifiques des données et aux analystes d'interagir avec les modèles d'apprentissage automatique sans avoir besoin de connaissances approfondies en matière de codage ou d'apprentissage automatique.
- Flexibilité du modèle : Prendre en charge une variété de modèles et d'algorithmes d'apprentissage automatique pour répondre à différents cas d'utilisation.
Technologies :
Python, Cloud run, Big Query, GCR, Teraform, Github Action
Principales réalisations :
L'architecture mise en œuvre a considérablement accéléré le processus de déploiement et de service des modèles d'apprentissage automatique. Actuellement, nous avons déployé 30 modèles sur Google Cloud Run, ce qui démontre l'évolutivité et la robustesse de la solution. En outre, notre architecture offre l'avantage d'intégrer de manière transparente des fonctions Python dans BigQuery, permettant même l'invocation d'API externes. Comme application pratique, nous avons déjà déployé des fonctions d'analyse de sentiment et de nettoyage de texte, permettant aux analystes de créer des nuages de mots et d'obtenir des scores de sentiment directement dans leur environnement BigQuery. Cette flexibilité améliore les capacités d'analyse des données et permet aux analystes d'effectuer des analyses plus sophistiquées sans quitter leur environnement préféré.